Redis在项目中的使用
基础
【Redis】对redis这个中间件进行深入学习,要会用,懂原理,并整理成博客记录 (配置文件详解:https://blog.csdn.net/w15558056319/article/details/121414742)
【Redis】用二进制文件安装Redis,设置密码为强密码:XXXXXXX,开放6379安全组 Redis学习中文网:https://redis.com.cn/
部署一个单机Redis(网上有一大堆好blog)
实战
【Redis】短信登录:
- 验证手机号以及生成验证码的工具类(hutool)
- 保存用户信息到Redis中可以隐藏用户敏感信息 Key唯一、Token(hutool)
- 状态登录刷新的问题(对于不需要拦截的路径)
【Redis】缓存三剑客:
- 为什么要使用缓存?
- 缓存模型和思路
- 缓存更新/淘汰策略(内存淘汰、超时剔除、主动更新)
- 数据库缓存不一致的问题(Cache Aside Pattern 人工编码方式:双写方案)三个问题:删除缓存还是更新缓存?如何保证缓存与数据库的操作的同时成功或失败?先操作缓存还是先操作数据库?(主要是两个操作之间所花时间的长短)
- 缓存穿透
- 缓存雪崩
- 缓存击穿(互斥锁[SETNX]、逻辑过期)
- 封装Redis工具类
【Redis】高并发下的线程安全:
- 分布式全局唯一ID(唯一性、高性能、安全性、递增性、高可用)(符号位、时间戳、序列号)
- 乐观锁解决超卖问题 (关键在于数据是否有被修改过 ) 常见的方法:1、版本号法 2、字段对比机制
UPDATE table_name
SET stock = stock - 1
WHERE voucher_id = ? AND stock > 0;为什么可以保证并发安全?(1)、UPDATE语句的原子性(2)、数据库的行级锁机制(3)、条件限制 (stock > 0) (4)、秒杀业务(一人一单)需要控制锁的粒度 synchronized
- 分布式锁redis:满足分布式系统或集群模式下多进程可见并且互斥的锁(可见性、互斥、高可用、高性能、安全性)常见的分布式锁有三种:MySQL(利用MySQL本身的互斥锁机制)、Redis(利用setnx这样的互斥命令,需要去深入学习这个的原理Lua脚本)、Zookeeper (1)、利用setnx方法的原子性 有过期时间防止死锁 (2)、会出现锁误删的情况(解决方法:存入线程标示)(3)、会出现原子性问题 (解决方法:使用Lua脚本解决多条命令原子性问题https://www.runoob.com/lua/lua-tutorial.html)Redis调用脚本的常见命令:help @scripting
- 分布式锁redission(重入问题(Lock-voaltile+state synchronized-count redission-hash(big-key、exprie、small-key))、不可重试、超时释放、主从一致性)(Lock + Synchronizer)
会出现的问题:(1)、事务与锁会发生事务还没提交(2)、锁就会释放的问题 事务与this会发生不生效的问题(this指向当前实例、代理对象的角色被绕过) 5. 异步秒杀思路:先利用Redis完成库存余量、一人一单判断,完成抢单业务,再将下单业务放入阻塞队列,利用独立线程异步下单
【Redis】排序方式 唯一性 查找方式 redis具体场景下的使用
- Redis消息队列(Stream支持消息持久化、支持阻塞读取、支持消息确认机制、支持消息回溯、受限于队列长度,消费堆积处理 可以利用消费者组提高消费速度,减少堆积)
- 点赞(set)
- 排行榜(sortedSet根据score值排序、唯一性为唯一、查找方式为根据元素查找)
- 共同关注(set 求交集)
- Feed流(拉模式、推模式、推拉结合)
- 附近商户 GEO(Geolocation)地理坐标
- 用户签到(BitMap)
- UV统计(UV:全称Unique Visitor,也叫独立访客量 PV:全称Page View,也叫页面访问量或点击量)Hyperloglog(HLL)是从Loglog算法派生的概率算法,也就是统计功能
【Redis】分布式缓存?单机的Redis的四大问题(数据丢失-持久化、并发能力-主从、存储能力-分片、故障恢复-哨兵)
Redis持久化
RDB持久化(Redis DataBase BackUp file)(Redis数据快照)
执行时机:四种情况(save、bgsave、停机、条件)
原理:fork主进程得到子进程(共享主进程内存数据)(copy-on-write技术)
问题:1、RDB方式bgsave的基本流程?2、RDB会在什么时候执行?save 60 1000代表什么含义?
缺点:执行间隔过长(数据丢失的风险)、耗时(fork、RDB)
AOF持久化(Append Only File)(追加文件)
原理:命令日志文件
配置:三种策略(always、everysec、no)
重写:bgrewriteaof
RDB与AOF对比(持久化方式、数据完整性、文件大小、宕机恢复速度、数据恢复优先级、系统资源占用、使用场景)
搭建主从架构-并发能力
搭建主从集群核心步骤:1、三个实例(replica-announce-ip)、三份不同配置(port) 2、开启主从关系(1、修改配置文件2、从节点执行命令)(replicaof + masterip + masterport) 3、主节点中查看集群状态:info replication 4、master-可以执行写 slave-只能执行读
- 全量同步原理 (Replication Id(是否为同一数据集)、offset(数据偏移量))

- 增量同步原理 (repl_backlog原理,全量同步的repl_baklog文件,是一个环形数组,角标到达数组末尾后,会再次从0开始读写)
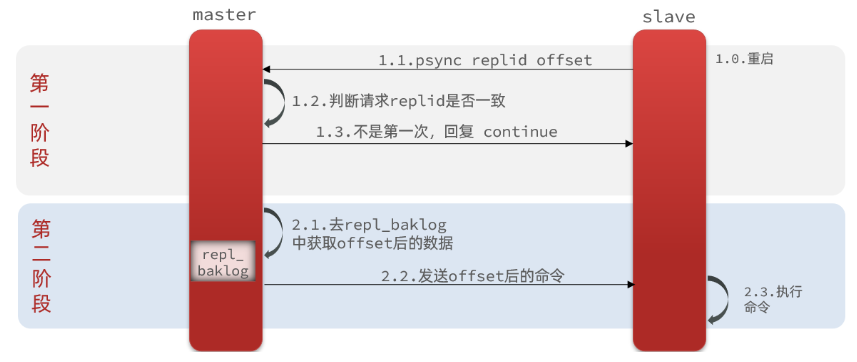
主从同步优化:1、在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。 2、Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO 3、适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步 4、限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
【Redis】多级缓存
- 什么是多级缓存?充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能
- 多级缓存两个关键:
- 一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询(Nginx不再是一个反向代理服务器,而是一个编写业务的web服务器)
- 另一个就在Tomcat中实现JVM进程缓存
- JVM进程缓存
- 缓存分为两类:1、分布式缓存,eg:Redis 2、进程本地缓存,eg:HashMap、GuavaCache
- Caffeine(近乎最佳命中率的高性能本地缓存)(性能遥遥领先)
- 基本API-构建Caffeine.newBuilder().build()-存put-取getIfPreset(key)、get(Key,Lambda)
- 三种缓存驱逐策略:1、基于容量maximumSize(1)2、基于时间.expireAfterWrite(Duration.ofSeconds(10)) 3、基于引用(NO)
- Lua语法入门
- 官网Lua
- OpenResty
- 官网OpenResty
- 介绍:是基于Nginx的高性能Web平台(处理高并发)(扩展性极高的动态Web应用)(Web服务和动态网关)
- 特点:1、具备Nginx的完整功能 2、基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块 3、允许使用Lua自定义业务逻辑、自定义库
- 缓存同步
- 缓存同步策略
- 设置有效期
- 同步双写
- 异步通知 (基于MQ(依然有少量的代码侵入)或者Canal(代码零侵入)实现)
- Canal
- 官网Canal
- 介绍:基于Java开发,基于数据库增量日志解析,提供增量数据订阅&消费
- MySQL主备复制原理:
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
- canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
我是怎么进行实现的,就是用第三方开源的canal-starter客户端,与springboot完美整合,自动装配 引入依赖 配置 数据表实体类 实现监听器接口(@CanalTable("表名")),重写insert、update、delete 的方法,可以将高性能的本地缓存Caffeine工具类、以及redis工具类统一注入依赖。